Diffusion Acceleration on CPU, GPU, FPGA
Accelerated U-Net diffusion across three embedded platforms; 1st in class.
Three sequential course projects in Embedded System Design (Fall 2024) targeting end-to-end inference latency of a U-Net-based diffusion model on three different embedded platforms. Each project was written up as a short paper.
CPU backend — Jetson Orin Nano. Implemented row-major im2col + GeMM with ARM NEON SIMD and OpenMP, optimized layernorm via parallel reduction with fused mean/variance computation, and fused conv2d with GELU and bias addition to cut memory traffic. End-to-end latency: 380.3 s → 28.0 s (13.58×). Report (PDF)
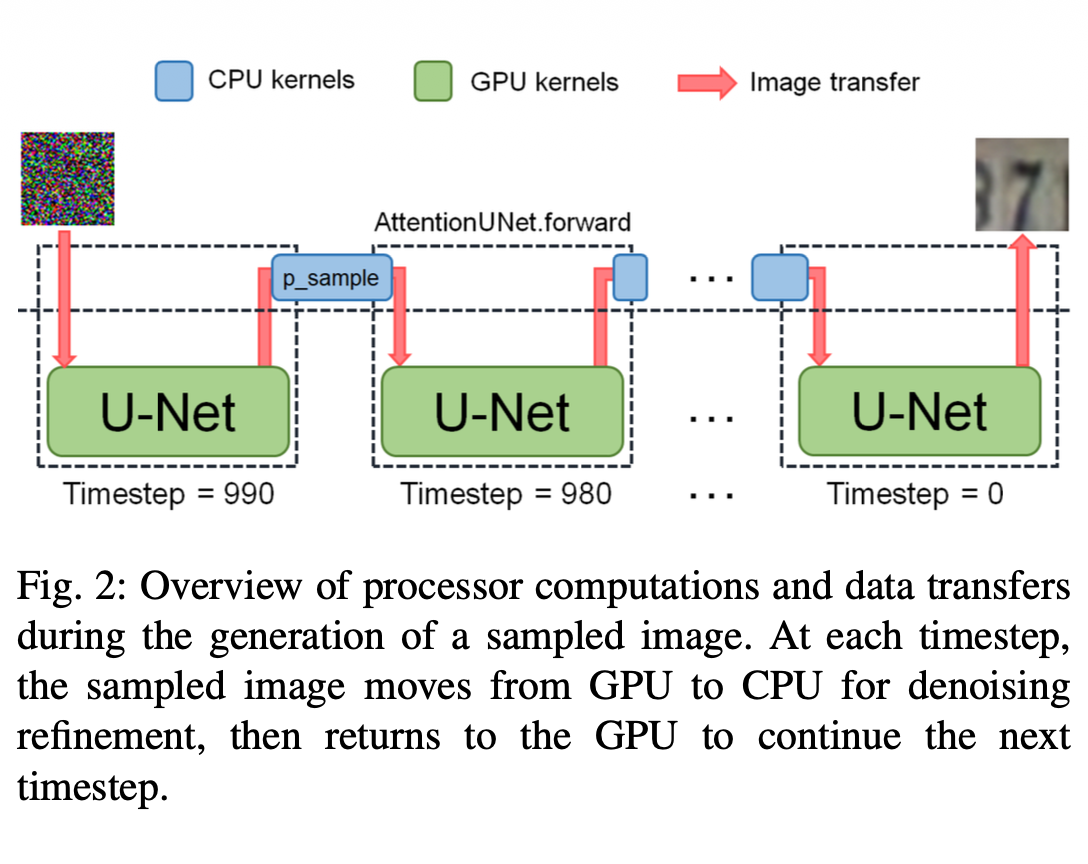
GPU backend — Jetson Orin Nano. Re-architected the pipeline so that all per-step computation runs on the GPU, with custom CUDA kernels using BF16 tensor cores for matmul, pre-allocated memory layouts that eliminate intra-GPU copies on skip connections, and asynchronous CPU↔GPU transfers overlapping computation and communication. End-to-end latency: 2.5 s (152.1× over baseline, 11.2× over the CPU version). Report (PDF)
FPGA backend — Xilinx Zynq-7000 with High-Level Synthesis (HLS). Designed a single-bitstream FP16 matmul accelerator with 3D tiling along M, K, and N, transposed-weight storage to balance DRAM burst lengths across the two AXI bundles, and a non-shared / shared memory split that avoids noncacheable-access penalties on the PS side. End-to-end latency: 455.4 s → 4.26 s (108.4×). Report (PDF)
Across the three projects I gained an end-to-end perspective on DNN acceleration spanning CPU SIMD, GPU CUDA with tensor cores, and FPGA HLS toolchains.